 無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!
無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!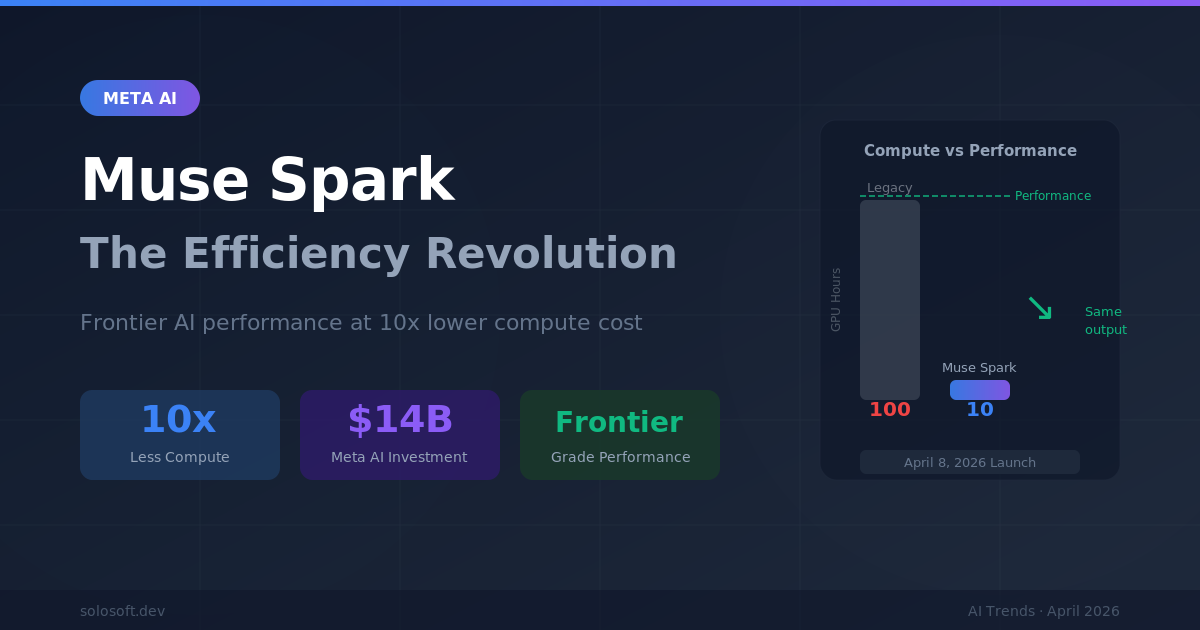
La suposición de que más grande es siempre mejor ha gobernado el desarrollo de la IA durante casi una década. Las leyes de escala, articuladas por primera vez por investigadores de OpenAI en 2020, sugerían que invertir más cómputo y datos en un modelo producía de manera confiable sistemas más inteligentes. Ese consenso moldeó decisiones de inversión de billones de dólares, planes de construcción de centros de datos, y el posicionamiento estratégico de cada laboratorio de IA importante. El 8 de abril de 2026, Meta desafió esa suposición de manera concreta: Muse Spark, el primer modelo importante de la compañía desde su compromiso de 14 mil millones de dólares en talento e infraestructura de IA, logra rendimiento competitivo en razonamiento multimodal, análisis de salud y completación de tareas agénticas—con un orden de magnitud menos cómputo que variantes anteriores de Llama 4. Esto no es meramente un lanzamiento de producto. Es una prueba de estrés de las suposiciones que impulsan la estrategia de IA en 2026.
El momento es significativo. OpenAI recientemente cerró una ronda récord de 122 mil millones de dólares a una valoración de 852 mil millones, con inversores que apuestan por un dominio continuo construido sobre escala de cómputo. Google DeepMind continúa invirtiendo fuertemente en clústeres de TPU para Gemini Ultra. En este contexto, la señal de Meta con prioridad en eficiencia tiene un peso estratégico que trasciende los benchmarks de modelos. Si un laboratorio bien financiado puede acercarse al rendimiento de frontera a una fracción del costo, el foso competitivo construido sobre el gasto puro en cómputo se estrecha. Para compradores empresariales, startups y gobiernos que consideran despliegues de IA, este desarrollo reformula el cálculo sobre en qué modelos apostar—y cuánto pagar.
¿Qué es Meta Muse Spark y por qué importa?
Meta Muse Spark es un modelo fundacional multimodal lanzado el 8 de abril de 2026, que combina razonamiento sólido, análisis en el dominio de salud y capacidades agénticas. Es el primer modelo insignia que surge de la ola de inversión de 14 mil millones de dólares que Meta anunció a finales de 2025, que incluyó la contratación de alto perfil del fundador de Scale AI, Alexandr Wang. Las ganancias de eficiencia—lograr rendimiento comparable a variantes anteriores de Llama 4 con un orden de magnitud menos cómputo—lo marcan como técnicamente distinto, no solo un refresco de marketing.
| Capacidad | Muse Spark | Llama 4 (referencia) | GPT-4o (estimado) |
|---|---|---|---|
| Percepción multimodal | ✅ Sólida | ✅ Sólida | ✅ Sólida |
| Benchmarks de razonamiento | Competitivo | Base | Competitivo |
| Completación de tareas agénticas | ✅ Mejorada | ⚠️ Limitada | ✅ Sólida |
| Cómputo de entrenamiento (relativo) | ~0.1x | 1x | ~1.5x |
| Dominio de salud | ✅ Especializado | ⚠️ General | ⚠️ General |
La reducción de cómputo es el titular. Una mejora de un orden de magnitud no es una ganancia incremental—es una señal de que las elecciones arquitectónicas, no solo la escala, están convirtiéndose en diferenciadores decisivos.
¿Por qué la eficiencia computacional se convierte en el nuevo foso competitivo?
Porque la ventaja estratégica de gastar más está erosionándose. Históricamente, el laboratorio que podía permitirse la mayor corrida de entrenamiento ganaba la carrera de capacidades. Muse Spark sugiere que la arquitectura—específicamente cómo un modelo integra el reconocimiento de patrones de redes neuronales con el razonamiento simbólico—puede compensar la escala cruda. La implicación es un cambio de una carrera armamentista definida por el gasto de capital a una definida por la calidad de la investigación.
La lógica económica es igualmente contundente. Con un costo de cómputo 10 veces menor, la inferencia se vuelve viable en mercados que anteriormente estaban excluidos: sistemas de salud rurales que operan en hardware comercial básico, gobiernos de mercados emergentes que despliegan servicios de IA con presupuestos limitados en la nube, y empresas de tamaño mediano que no pueden justificar los costos de API de frontera. La democratización no es solo una afirmación de marketing aquí—es un resultado aritmético del cómputo más barato.
graph TD
A[Alto costo de cómputo] --> B[Solo grandes empresas pueden permitirse IA de frontera]
C[Avance de eficiencia Muse Spark] --> D[Costo de inferencia 10x menor]
D --> E[Diagnósticos médicos accesibles]
D --> F[Despliegues en mercados emergentes viables]
D --> G[Empresas medianas competitivas]
D --> H[Nuevos casos de uso agénticos desbloqueados]
B -->|estado anterior| I[Acceso a IA concentrado]
G --> J[Acceso a IA distribuido]¿Cómo cambia Muse Spark la economía del despliegue de IA?
Desplaza el punto de equilibrio para la adopción de IA en un orden de magnitud. Considera un sistema hospitalario que ejecuta asistencia diagnóstica en 10,000 registros de pacientes diariamente. Con los precios anteriores de modelos de frontera, esta carga de trabajo podría costar entre 50,000 y 80,000 dólares al mes. Con una eficiencia 10 veces mayor, la misma carga de trabajo cae por debajo de 10,000 dólares—bien dentro del presupuesto operativo de un hospital de tamaño mediano. Esto no es teórico: Meta ha destacado la salud como un dominio de enfoque específico para Muse Spark.
| Escenario de despliegue | Costo estimado anterior | Estimado Muse Spark | Cambio de accesibilidad |
|---|---|---|---|
| Asistencia diagnóstica hospitalaria (10K registros/día) | $60K/mes | ~$6K/mes | ✅ Ahora viable para hospitales medianos |
| Revisión de documentos legales (50K páginas/mes) | $40K/mes | ~$4K/mes | ✅ Despachos jurídicos PYME pueden adoptar |
| QA en manufactura (1M verificaciones de imagen/día) | $120K/mes | ~$12K/mes | ✅ Competitivo con QA humano |
| Servicio al cliente agéntico (1M interacciones/mes) | $80K/mes | ~$8K/mes | ✅ Viable para startups Serie A |
Estas son estimaciones ilustrativas basadas en ratios de reducción de cómputo reportados y benchmarks actuales de precios de API. Los costos reales dependen de la infraestructura de despliegue y la optimización.
¿Es la ganancia de eficiencia un avance genuino o manipulación de benchmarks?
Esta es la pregunta correcta, y el escepticismo está justificado. Los desarrolladores de modelos tienen un historial documentado de seleccionar benchmarks que favorecen su arquitectura y distribución de entrenamiento. Se necesita evaluación independiente en las suites completas de MMLU, HELM y BIG-Bench, así como en tareas agénticas del mundo real, antes de aceptar las afirmaciones de eficiencia al pie de la letra.
Dicho esto, el mecanismo reportado—combinar reconocimiento de patrones de redes neuronales con componentes de razonamiento simbólico—tiene fundamento teórico. Las arquitecturas híbridas reducen el cómputo redundante al descargar tareas con restricciones de reglas a módulos simbólicos en lugar de forzar a la red neuronal a aprenderlas de ejemplos. Esto es conceptualmente similar a las ganancias de eficiencia vistas en modelos de mezcla de expertos (MoE), donde solo un subconjunto de parámetros se activa por token.
flowchart LR
Input[Entrada del usuario] --> Router{Enrutador de tareas}
Router -->|Tareas intensivas en patrones| NN[Modulo de red neuronal]
Router -->|Tareas con restricciones de reglas| Sym[Modulo de razonamiento simbolico]
NN --> Merge[Agregador de salida]
Sym --> Merge
Merge --> Output[Respuesta]
style NN fill:#4A90D9,color:#fff
style Sym fill:#F5A623,color:#fff
style Router fill:#7ED321,color:#fffLa preocupación legítima es si los módulos simbólicos introducen fragilidad—degradándose en casos extremos fuera de su espacio de reglas. El enfoque de Meta en el dominio de salud pondrá esto a prueba: el razonamiento médico involucra tanto reconocimiento de patrones (imágenes diagnósticas) como lógica con restricciones de reglas (verificación de interacciones medicamentosas), lo que lo convierte en un campo de prueba apropiado.
¿Qué significa esto para OpenAI, Google y Nvidia?
Para OpenAI y Google DeepMind, Muse Spark obliga a una revaluación estratégica. Si un competidor logra rendimiento de nivel frontera con 10 veces menos cómputo, la narrativa que justificó los 122 mil millones de dólares en financiamiento de OpenAI—que el dominio requiere escala de cómputo incomparable—está al menos parcialmente socavada. Ninguno de los dos laboratorios abandonará el escalado; ambos también necesitarán demostrar ganancias de eficiencia.
Para Nvidia, las implicaciones son matizadas. Una reducción de 10x en cómputo por tarea no significa automáticamente 10x menos ventas de GPU—el efecto de elasticidad históricamente impulsa la demanda: la IA más barata desbloquea nuevas aplicaciones, expandiendo el mercado total direccionable. Sin embargo, si los compradores empresariales comienzan a especificar despliegues en torno a modelos con prioridad en eficiencia, la dinámica del ciclo de actualización cambia.
| Parte interesada | Impacto a corto plazo | Riesgo a largo plazo |
|---|---|---|
| OpenAI | Presión narrativa sobre la tesis de escala | Podría perder segmento empresarial sensible al costo |
| Google DeepMind | Obliga a inversión en I+D de eficiencia | Ventaja TPU parcialmente commoditizada |
| Nvidia | Elasticidad de demanda probablemente compensa eficiencia | Ciclo de actualización más lento si las ganancias de eficiencia se acumulan |
| AWS / Azure / GCP | Requisitos de clúster menores por carga de trabajo | Posible reducción de capex en aprovisionamiento de GPU |
| Compradores empresariales | Oportunidad inmediata de reducción de costos | Mayor riesgo de diversificación de proveedores |
¿Cuáles son los límites y modos de fallo a vigilar?
La narrativa de eficiencia tiene restricciones reales que vale la pena probar antes de hacer apuestas estratégicas.
Primero, los módulos de razonamiento simbólico son frágiles en los límites de distribución. Las ganancias de Muse Spark en el dominio de salud pueden no transferirse a escritura creativa, generación de código o tareas de razonamiento intercultural donde las reglas son ambiguas o contestadas. Cualquier empresa que considere reemplazar un modelo incumbent debe realizar evaluaciones específicas de tareas, no confiar en benchmarks publicados.
Segundo, las afirmaciones de eficiencia multimodal merecen escrutinio en entradas de imagen y video. Las ganancias de eficiencia en lenguaje no se generalizan automáticamente a entradas de alta dimensión—la reducción de cómputo puede estar concentrada en tareas de texto mientras que la sobrecarga de procesamiento de imágenes permanece igual.
Tercero, la pregunta de API abierta versus cerrada sigue sin resolverse. Si Meta retiene Muse Spark como producto de API cerrada (en lugar de abrir el código fuente de los pesos), el argumento de democratización está condicionado a las decisiones de precios de Meta, no a una garantía arquitectónica.
Preguntas frecuentes
¿Qué es Meta Muse Spark? Meta Muse Spark es el modelo fundacional más reciente de Meta, lanzado en abril de 2026, que ofrece razonamiento multimodal competitivo y capacidades agénticas con requisitos de cómputo drásticamente menores que variantes anteriores de Llama 4—aproximadamente un orden de magnitud menos.
¿Por qué importa la eficiencia computacional en IA? Los menores requisitos de cómputo reducen los costos de entrenamiento e inferencia, permitiendo que organizaciones más pequeñas desplieguen IA de vanguardia. También reduce el consumo energético y la huella de carbono.
¿Cómo se compara Muse Spark con GPT-4o y Gemini Ultra? Los primeros benchmarks ubican a Muse Spark dentro del rango de GPT-4o en tareas de razonamiento y multimodales, con significativamente menos horas-GPU de entrenamiento. Las comparaciones directas contra Gemini Ultra siguen siendo preliminares.
¿Cuál es el significado de la inversión de 14 mil millones detrás de Muse Spark? Meta comprometió 14 mil millones de dólares en talento e infraestructura de IA en 2025–2026, incluyendo la contratación de Alexandr Wang. Muse Spark es el primer modelo importante que surge de esta inversión, señalando que Meta está pasando de seguidor a competidor de frontera.
¿La eficiencia computacional implica sacrificar calidad en IA? No. La arquitectura de Muse Spark mejora la precisión junto con las ganancias de eficiencia, lo que sugiere un avance arquitectónico genuino en lugar de una compensación calidad-costo.
¿Qué industrias se benefician más? El diagnóstico médico, el análisis de documentos legales y el control de calidad en manufactura son los beneficiarios más claros a corto plazo.
¿Es la eficiencia en IA una amenaza para el dominio de Nvidia en GPU? Potencialmente a largo plazo, aunque el efecto de elasticidad de la demanda podría compensar el impacto a corto plazo.
Lectura adicional
- Blog de Investigación de Meta AI — Fuente oficial de artículos técnicos y tarjetas de modelo de Muse Spark
- CNBC: Meta presenta su primer modelo de IA importante desde el acuerdo de 14 mil millones — Cobertura original del lanzamiento del 8 de abril
- ScienceDaily: Reducción de energía de IA 100x mientras mejora la precisión — Investigación sobre ganancias de eficiencia híbrida neuronal-simbólica
- Stanford HAI AI Index 2026 — Benchmark anual para capacidades, costos y tendencias de acceso a la IA