 無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!
無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!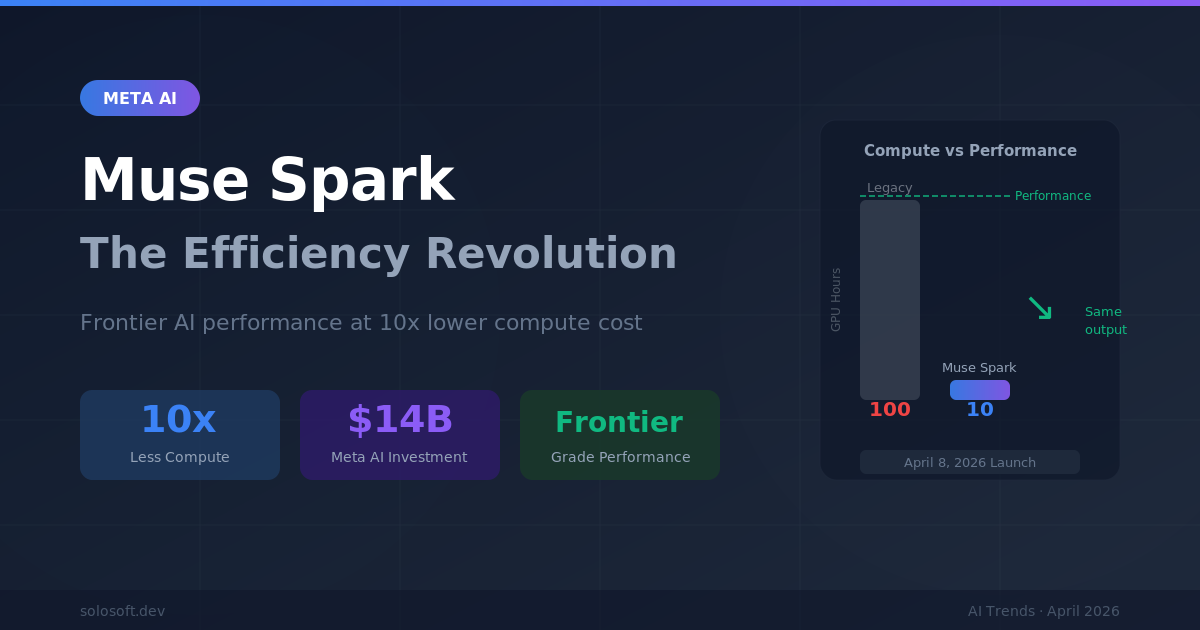
The assumption that bigger is always better has governed AI development for nearly a decade. Scaling laws, first articulated by OpenAI researchers in 2020, suggested that pouring more compute and data into a model reliably produced smarter systems. That consensus shaped trillion-dollar investment decisions, data center build-outs, and the strategic positioning of every major AI lab. On April 8, 2026, Meta challenged that assumption in a concrete way: Muse Spark, the company’s first major model since its $14 billion AI talent and infrastructure commitment, achieves competitive performance on multimodal reasoning, health analysis, and agentic task completion—at reportedly an order of magnitude less compute than prior Llama 4 variants. This is not merely a product launch. It is a stress test of the assumptions driving AI strategy in 2026.
The timing is significant. OpenAI recently closed a record $122 billion funding round at an $852 billion valuation, with investors pricing in continued dominance built on compute scale. Google DeepMind continues to invest heavily in TPU clusters for Gemini Ultra. Against this backdrop, Meta’s efficiency-first signal carries strategic weight that transcends model benchmarks. If a well-resourced lab can approach frontier performance at a fraction of the cost, the competitive moat built on sheer compute spending narrows. For enterprise buyers, startups, and governments considering AI deployments, this development reframes the calculus on which models to bet on—and how much to pay.
What Is Meta Muse Spark and Why Does It Matter?
Meta Muse Spark is a multimodal foundation model released on April 8, 2026, combining strong reasoning, health-domain analysis, and agentic capabilities. It is the first flagship model to emerge from the $14 billion investment wave Meta announced in late 2025, which included a high-profile hire of Scale AI founder Alexandr Wang. The efficiency gains—achieving comparable performance to older Llama 4 variants with an order of magnitude less compute—mark it as technically distinct, not just a marketing refresh.
| Capability | Muse Spark | Llama 4 (reference) | GPT-4o (estimated) |
|---|---|---|---|
| Multimodal perception | ✅ Strong | ✅ Strong | ✅ Strong |
| Reasoning benchmarks | Competitive | Baseline | Competitive |
| Agentic task completion | ✅ Enhanced | ⚠️ Limited | ✅ Strong |
| Training compute (relative) | ~0.1x | 1x | ~1.5x |
| Health domain | ✅ Specialized | ⚠️ General | ⚠️ General |
The compute reduction is the headline. An order-of-magnitude improvement is not an incremental gain—it is a signal that architectural choices, not just scale, are becoming decisive differentiators.
Why Does Compute Efficiency Become the New Competitive Moat?
Because the strategic advantage of spending more is eroding. Historically, the lab that could afford the largest training run won the capability race. Muse Spark suggests that architecture—specifically how a model integrates neural network pattern recognition with symbolic reasoning—can compensate for raw scale. The implication is a shift from an arms race defined by capital expenditure to one defined by research quality.
The economic logic is equally forceful. At 10x lower compute cost, inference becomes viable in markets that were previously locked out: rural healthcare systems running on commodity hardware, emerging market governments deploying AI services on limited cloud budgets, and mid-size enterprises that cannot justify frontier API costs. Democratization is not just a marketing claim here—it is an arithmetic outcome of cheaper compute.
graph TD
A[Higher Compute Cost] --> B[Only large enterprises can afford frontier AI]
C[Muse Spark Efficiency Breakthrough] --> D[10x lower inference cost]
D --> E[Healthcare diagnostics accessible]
D --> F[Emerging market deployments viable]
D --> G[Mid-size enterprises competitive]
D --> H[New agentic use cases unlocked]
B -->|previous state| I[AI access concentrated]
G --> J[AI access distributed]How Does Muse Spark Change the Economics of AI Deployment?
It shifts the breakeven point for AI adoption by an order of magnitude. Consider a hospital system running diagnostic assistance across 10,000 patient records daily. At prior frontier model pricing, this workload might cost $50,000–$80,000 per month. At 10x efficiency, the same workload drops below $10,000—well within a mid-size hospital’s operational budget. This is not theoretical: Meta has highlighted health as a specific focus domain for Muse Spark.
| Deployment Scenario | Previous Cost Estimate | Muse Spark Estimate | Accessibility Change |
|---|---|---|---|
| Hospital diagnostic assist (10K records/day) | $60K/mo | ~$6K/mo | ✅ Now viable for mid-size |
| Legal doc review (50K pages/month) | $40K/mo | ~$4K/mo | ✅ SMB law firms can now adopt |
| Manufacturing QA (1M image checks/day) | $120K/mo | ~$12K/mo | ✅ Cost-competitive with human QA |
| Agentic customer service (1M interactions/mo) | $80K/mo | ~$8K/mo | ✅ Viable for Series A startups |
These are illustrative estimates based on reported compute reduction ratios and current API pricing benchmarks. Actual costs depend on deployment infrastructure and optimization.
Is the Efficiency Gain a Genuine Breakthrough or a Benchmark Manipulation?
This is the right question, and skepticism is warranted. Model developers have a documented history of selecting benchmarks that favor their architecture and training distribution. Independent evaluation on the full MMLU, HELM, and BIG-Bench suites, as well as real-world agentic tasks, is needed before accepting efficiency claims at face value.
That said, the mechanism being reported—combining neural pattern recognition with symbolic reasoning components—has theoretical grounding. Hybrid architectures reduce redundant computation by offloading rule-bound tasks to symbolic modules rather than forcing the neural network to learn them from examples. This is conceptually similar to the efficiency gains seen in mixture-of-experts (MoE) models, where only a subset of parameters are activated per token.
flowchart LR
Input[User Input] --> Router{Task Router}
Router -->|Pattern-heavy tasks| NN[Neural Network Module]
Router -->|Rule-bound tasks| Sym[Symbolic Reasoning Module]
NN --> Merge[Output Aggregator]
Sym --> Merge
Merge --> Output[Response]
style NN fill:#4A90D9,color:#fff
style Sym fill:#F5A623,color:#fff
style Router fill:#7ED321,color:#fffThe legitimate concern is whether symbolic modules introduce brittleness—degrading on edge cases outside their rule space. Meta’s health domain focus will stress-test this: medical reasoning involves both pattern recognition (diagnostic imaging) and rule-bound logic (drug interaction checking), making it an apt proving ground.
What Does This Mean for OpenAI, Google, and Nvidia?
For OpenAI and Google DeepMind, Muse Spark forces a strategic reappraisal. If a competitor achieves frontier-grade performance at 10x lower compute, the narrative that justified $122 billion in OpenAI funding—that dominance requires unmatched compute scale—is at least partially undermined. Neither lab will abandon scaling; both will also need to demonstrate efficiency gains.
For Nvidia, the implications are nuanced. A 10x reduction in compute per task does not automatically mean 10x fewer GPU sales—the elasticity effect historically drives demand: cheaper AI unlocks new applications, expanding the total addressable market. However, if enterprise buyers begin spec’ing deployments around efficiency-first models, the upgrade cycle dynamics change, and the pace of data center GPU refreshes may slow.
| Stakeholder | Short-Term Impact | Long-Term Risk |
|---|---|---|
| OpenAI | Narrative pressure on scale thesis | Could lose enterprise cost-sensitive segment |
| Google DeepMind | Forces efficiency R&D investment | TPU advantage partially commoditized |
| Nvidia | Demand elasticity likely offsets efficiency | Slower upgrade cycle if efficiency gains compound |
| AWS / Azure / GCP | Smaller cluster requirements per workload | Potential capex reduction in GPU provisioning |
| Enterprise buyers | Immediate cost reduction opportunity | Vendor diversification risk increases |
What Are the Limits and Failure Modes to Watch?
The efficiency narrative has real constraints that are worth stress-testing before making strategic bets.
First, symbolic reasoning modules are brittle at distribution boundaries. Muse Spark’s health domain gains may not transfer to creative writing, code generation, or cross-cultural reasoning tasks where rules are fuzzy or contested. Any enterprise considering replacing an incumbent model should run task-specific evaluations, not rely on published benchmarks.
Second, multimodal efficiency claims deserve scrutiny on image and video inputs. Language efficiency gains do not automatically generalize to high-dimensional inputs—the compute reduction may be concentrated in text tasks while image processing overhead remains.
Third, the open vs. closed API question remains unresolved. If Meta retains Muse Spark as a closed API product (rather than open-sourcing weights), the democratization argument is conditional on Meta’s pricing decisions, not an architectural guarantee.
FAQ
What is Meta Muse Spark? Meta Muse Spark is Meta’s latest foundation model, released in April 2026, delivering competitive multimodal reasoning and agentic capabilities at dramatically lower compute requirements than prior Llama 4 variants—reportedly an order of magnitude less.
Why does AI compute efficiency matter? Lower compute requirements reduce training and inference costs, allowing smaller organizations to deploy frontier-grade AI. It also shrinks energy consumption and carbon footprint, addressing one of the biggest sustainability criticisms of large-scale AI development.
How does Muse Spark compare to GPT-4o and Gemini Ultra? Early benchmarks place Muse Spark within range of GPT-4o on reasoning and multimodal tasks, while requiring significantly less GPU-hours to train. Direct comparisons against Gemini Ultra on agentic benchmarks remain preliminary.
What is the significance of the $14 billion AI investment behind Muse Spark? Meta committed $14 billion to AI talent and infrastructure in 2025–2026, including hiring Alexandr Wang. Muse Spark is the first major model to emerge from this investment, signaling that Meta is shifting from fast-follower to frontier competitor.
Does compute efficiency mean AI quality is being sacrificed? No. Muse Spark’s architecture improves accuracy alongside efficiency gains, suggesting a genuine architectural breakthrough rather than a quality-cost tradeoff. Combining neural networks with symbolic reasoning components appears to be the key mechanism.
What industries benefit most from cheaper AI inference? Healthcare diagnostics, legal document analysis, and manufacturing quality control are the clearest near-term beneficiaries—all sectors where high inference volume was previously cost-prohibitive with frontier models.
Is AI efficiency a threat to Nvidia’s GPU dominance? Potentially in the long term. If leading models achieve comparable results with 10x fewer GPU-hours, demand growth for raw compute could slow. However, the elasticity effect—cheaper inference enabling entirely new use cases—may sustain or increase overall GPU demand.
Further Reading
- Meta AI Research Blog — Official source for Muse Spark technical papers and model cards
- CNBC: Meta Debuts First Major AI Model Since $14 Billion Deal — Original reporting on the April 8 launch
- ScienceDaily: 100x AI Energy Reduction While Improving Accuracy — Research on hybrid neural-symbolic efficiency gains
- Stanford HAI AI Index 2026 — Annual benchmark for AI capabilities, costs, and access trends