 無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!
無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!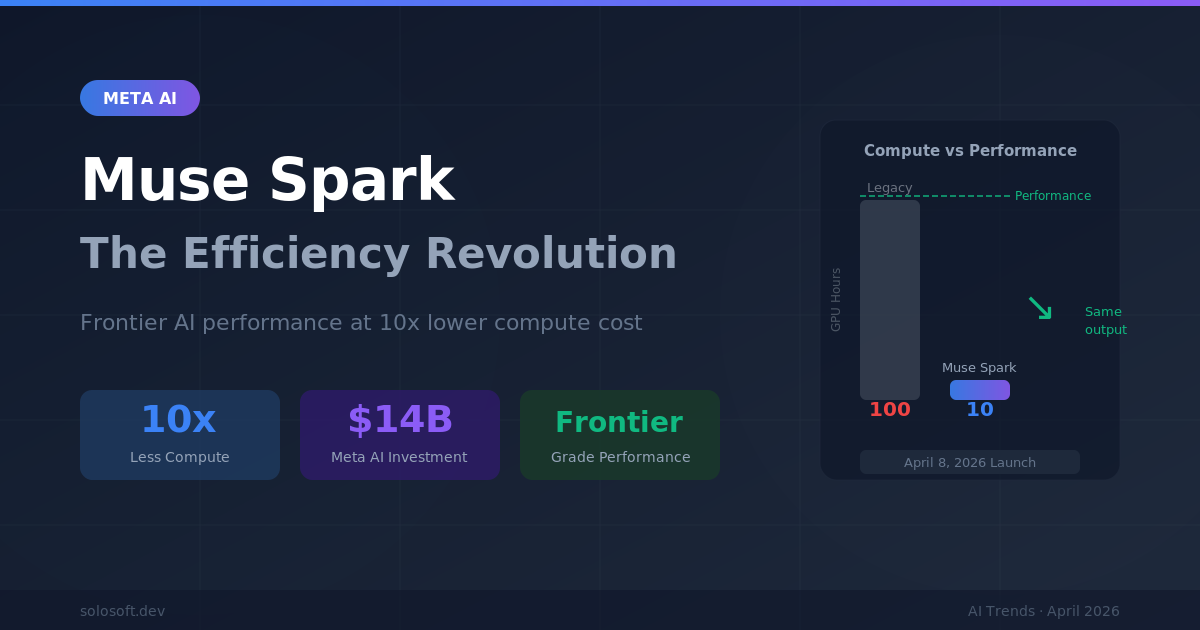
「越大越好」的假设主导了 AI 发展将近十年。2020 年由 OpenAI 研究人员提出的扩展定律指出,向模型投入更多算力与数据能可靠地产生更智能的系统。这个共识塑造了数万亿美元的投资决策、数据中心建设规划,以及每家主要 AI 实验室的战略定位。2026 年 4 月 8 日,Meta 以具体行动挑战了这个假设:Muse Spark——Meta 自 140 亿美元 AI 人才与基础设施承诺以来的首款重要模型——在多模态推理、健康分析与智能体任务完成方面表现出竞争力,所需算力比旧版 Llama 4 据报少了约一个数量级。这不只是一次产品发布,而是对 2026 年 AI 战略假设的一次压力测试。
时机意义深远。OpenAI 近期以 8520 亿美元估值完成了创纪录的 1220 亿美元融资,投资人押注的是建立在算力规模上的持续主导地位。谷歌 DeepMind 持续大力投资 Gemini Ultra 的 TPU 集群。在此背景下,Meta 以效率优先的信号所带来的战略分量,远超出模型基准测试本身。若一家资源充沛的实验室能以成本的一小部分接近前沿性能,单纯靠算力支出建立的竞争护城河就会收窄。对于评估 AI 部署的企业买家、初创公司与政府而言,这一进展重新框架了押注哪些模型、愿意支付多少费用的计算逻辑。
Meta Muse Spark 是什么,为何重要?
Meta Muse Spark 是 2026 年 4 月 8 日发布的多模态基础模型,结合了强大的推理、健康领域分析与智能体能力。这是 Meta 在 2025 年底宣布的 140 亿美元投资浪潮——包括高调引进 Scale AI 创始人 Alexandr Wang——所诞生的首款旗舰模型。效率提升——以少约一个数量级的算力达到与旧版 Llama 4 相当的性能——标志着它在技术上的独特性,而非只是营销包装。
| 能力 | Muse Spark | Llama 4(参考) | GPT-4o(估计) |
|---|---|---|---|
| 多模态感知 | ✅ 强 | ✅ 强 | ✅ 强 |
| 推理基准 | 具竞争力 | 基准 | 具竞争力 |
| 智能体任务完成 | ✅ 增强 | ⚠️ 有限 | ✅ 强 |
| 训练算力(相对) | ~0.1x | 1x | ~1.5x |
| 健康领域 | ✅ 专业化 | ⚠️ 通用 | ⚠️ 通用 |
算力减少是最大亮点。提升一个数量级并非渐进式改善——这是架构选择而非规模正在成为决定性差异化因素的信号。
为何算力效率成为新的竞争护城河?
因为「多花钱就能赢」的战略优势正在侵蚀。过去,能负担最大训练规模的实验室就能赢得能力竞赛。Muse Spark 的案例表明,架构——特别是模型如何将神经网络模式识别与符号推理整合在一起——能够弥补原始规模的不足。这意味着竞争格局从以资本支出定义的军备竞赛,转向以研究质量定义的竞争。
经济逻辑同样有力。以低 10 倍的算力成本,推理在过去被排除在外的市场中变得可行:使用普通商用硬件的农村医疗系统、在有限云端预算下部署 AI 服务的新兴市场政府,以及无法承担前沿 API 成本的中型企业。民主化不再只是营销话术——它是更低廉算力的算术结果。
graph TD
A[高昂算力成本] --> B[只有大型企业能负担前沿 AI]
C[Muse Spark 效率突破] --> D[推理成本降低 10 倍]
D --> E[医疗诊断变得可及]
D --> F[新兴市场部署成为可能]
D --> G[中型企业具备竞争力]
D --> H[新智能体应用场景解锁]
B -->|过去状态| I[AI 使用权集中]
G --> J[AI 使用权分散]Muse Spark 如何改变 AI 部署的经济学?
它将 AI 采用的盈亏平衡点移动了一个数量级。试想一家医院系统每天对 10,000 份患者记录执行诊断辅助。按过去的前沿模型定价,这样的工作量每月可能耗费 5 至 8 万美元。效率提升 10 倍后,相同工作量降至 1 万美元以下——完全在中型医院的运营预算范围内。这并非纯粹理论:Meta 已明确将健康列为 Muse Spark 的重点应用领域。
| 部署场景 | 过去成本估计 | Muse Spark 估计 | 可及性变化 |
|---|---|---|---|
| 医院诊断辅助(每日 1 万条) | 6 万美元/月 | 约 6 千美元/月 | ✅ 中型医院现可负担 |
| 法律文件审查(每月 5 万页) | 4 万美元/月 | 约 4 千美元/月 | ✅ 中小型律所可采用 |
| 制造业质检(每日 100 万次图像检测) | 12 万美元/月 | 约 1.2 万美元/月 | ✅ 与人工质检成本相当 |
| 智能体客服(每月 100 万次交互) | 8 万美元/月 | 约 8 千美元/月 | ✅ A 轮初创可承担 |
以上为基于报告算力减少比例与当前 API 定价基准的示意估算,实际成本取决于部署基础设施与优化程度。
效率提升是真正的突破还是基准测试操纵?
这是正确的问题,保持怀疑是合理的。模型开发者有挑选有利于自身架构与训练分布之基准的记录。在全面的 MMLU、HELM 与 BIG-Bench 测试组,以及真实世界智能体任务上进行独立评估,是接受效率声明之前的必要步骤。
话虽如此,所描述的机制——结合神经模式识别与符号推理组件——有其理论基础。混合架构将规则受限的任务卸载至符号模块,减少了神经网络从范例中学习这些任务的冗余计算。这在概念上类似于混合专家(MoE)模型的效率提升,后者每个 token 只激活部分参数。
flowchart LR
Input[用户输入] --> Router{任务路由器}
Router -->|模式密集型任务| NN[神经网络模块]
Router -->|规则受限型任务| Sym[符号推理模块]
NN --> Merge[输出聚合器]
Sym --> Merge
Merge --> Output[响应]
style NN fill:#4A90D9,color:#fff
style Sym fill:#F5A623,color:#fff
style Router fill:#7ED321,color:#fff合理的疑虑在于符号模块在分布边界之外是否会变得脆弱——在其规则空间之外的边缘案例上可能退化。Meta 对健康领域的聚焦将对此进行压力测试:医疗推理同时涉及模式识别(诊断影像)和规则受限逻辑(药物相互作用检查),是一个适当的试炼场。
这对 OpenAI、谷歌和英伟达意味着什么?
对于 OpenAI 和谷歌 DeepMind,Muse Spark 迫使他们重新评估战略。若竞争对手以低 10 倍的算力达到前沿等级性能,支撑 OpenAI 1220 亿美元融资的叙事——主导地位需要无与伦比的算力规模——至少部分受到了动摇。两家公司都不会放弃规模扩张;但也都需要展示效率提升。
对于英伟达,影响更为复杂。每项任务算力减少 10 倍并不自动意味着 GPU 销售减少 10 倍——需求弹性效应历史上会推动需求:更便宜的 AI 解锁新应用,扩大总体可及市场。然而,若企业买家开始以效率优先模型为基础规划部署,升级周期动态将改变,数据中心 GPU 更新节奏可能放缓。
| 利益相关方 | 短期影响 | 长期风险 |
|---|---|---|
| OpenAI | 规模论叙事承压 | 可能流失对成本敏感的企业客群 |
| 谷歌 DeepMind | 被迫加大效率研发投资 | TPU 优势部分商品化 |
| 英伟达 | 需求弹性效应可能抵消效率冲击 | 若效率增益持续积累,升级周期可能放缓 |
| AWS / Azure / GCP | 每项工作负载所需集群规模缩小 | GPU 供应资本支出可能减少 |
| 企业买家 | 即时降低成本的机会 | 供应商多元化风险上升 |
有哪些值得关注的限制与失败模式?
效率叙事有其真实的局限性,在做出战略押注前值得仔细审视。
首先,符号推理模块在分布边界上容易脆化。Muse Spark 在健康领域的提升可能无法迁移至创意写作、代码生成或跨文化推理等规则模糊的任务。考虑替换现有模型的企业应执行特定任务评估,而非仅依赖已发布的基准。
其次,多模态效率声明在图像与视频输入上值得审视。语言效率提升并不自动推广至高维输入——算力减少可能集中于文字任务,而图像处理开销仍维持不变。
第三,开放与封闭 API 的问题仍悬而未决。若 Meta 以封闭 API 产品形式保留 Muse Spark(而非开源模型权重),民主化论点的成立前提是 Meta 的定价决策,而非架构保证。
常见问题
Meta Muse Spark 是什么? Meta Muse Spark 是 Meta 于 2026 年 4 月发布的最新基础模型,在多模态推理与智能体任务方面表现卓越,所需算力比旧版 Llama 4 少了约一个数量级。
AI 算力效率为何如此重要? 较低的算力需求可大幅降低训练与推理成本,让规模较小的机构也能部署前沿 AI。同时也能缩减能耗与碳足迹,回应外界对大规模 AI 开发的可持续性质疑。
Muse Spark 与 GPT-4o 和 Gemini Ultra 相比如何? 早期基准测试显示,Muse Spark 在推理和多模态任务上的表现与 GPT-4o 相当,但所需 GPU 训练时间显著更少。与 Gemini Ultra 在智能体基准上的直接比较仍属初步阶段。
Muse Spark 背后 140 亿美元投资的意义是什么? Meta 在 2025 至 2026 年间承诺投入 140 亿美元于 AI 人才与基础设施,包括引进 Alexandr Wang。Muse Spark 是这波投资中诞生的首款旗舰模型,标志着 Meta 从跟随者转型为前沿竞争者。
算力效率提升意味着 AI 质量的妥协吗? 不。Muse Spark 的架构在提升效率的同时也改善了准确率,表明这是真正的架构突破,而非性能与成本的妥协。
哪些行业最受益于更低廉的 AI 推理成本? 医疗诊断、法律文件分析与制造业质检是近期最明确的受益者。
AI 效率是否威胁到英伟达的 GPU 主导地位? 长期而言可能如此。若顶尖模型以少 10 倍的 GPU 时数达成相当结果,原始算力的需求增长可能放缓。不过,需求弹性效应可能维持甚至增加整体 GPU 需求。
延伸阅读
- Meta AI 研究博客 — Muse Spark 技术论文与模型说明的官方来源
- CNBC:Meta 发布自 140 亿美元交易以来的首款重要 AI 模型 — 4 月 8 日发布的原始报道
- ScienceDaily:AI 能耗降低 100 倍同时提升准确率 — 神经符号混合效率提升研究
- Stanford HAI AI Index 2026 — AI 能力、成本与普及趋势的年度基准


