
Causal-Conv1d:驱动 Mamba 状态空间模型的 CUDA 优化内核
Transformer 架构已主宰深度学习多年,但一个新的挑战者已经出现:状态空间模型(SSM)。在最具影响力的 SSM 架构之一 Mamba 的核心,是一个名为 Causal-Conv1d 的、令人惊讶地简朴的 CUDA 内核库。由 Tri Dao(以 FlashAttention 闻名 …
Transformer 架构已主宰深度学习多年,但一个新的挑战者已经出现:状态空间模型(SSM)。在最具影响力的 SSM 架构之一 Mamba 的核心,是一个名为 Causal-Conv1d 的、令人惊讶地简朴的 CUDA 内核库。由 Tri Dao(以 FlashAttention 闻名 …
多年来,AI 社区一直处在一个广为接受的假设之下:Transformer 架构——在里程碑式的「Attention Is All You Need」论文中首次提出——是构建大型语言模型的唯一可行途径。递归神经网络(RNN)被认为已经过时——训练太慢、太容易出现梯度消失、无法在规模上匹配 …
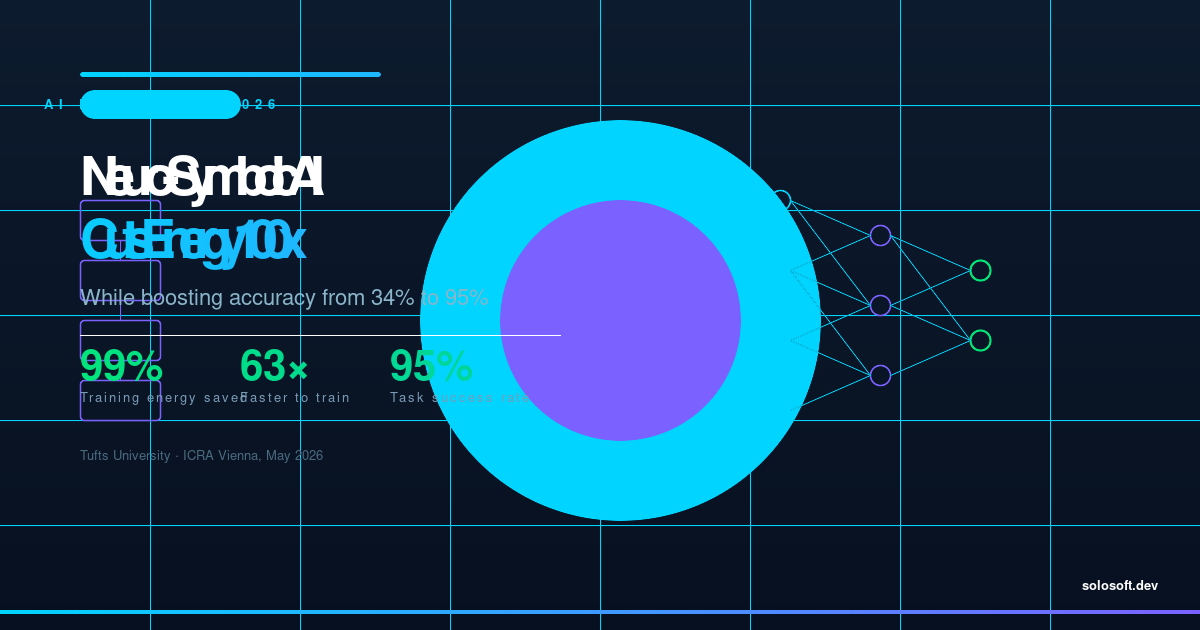
AI 产业在过去五年通过扩展规模来获取更强大的模型——增加参数、消耗更多算力,以令电网运营商从弗吉尼亚到新加坡都警觉的速度吞噬电力。2026 年 4 月,塔夫茨大学研究团队发布了一项成果,从根本挑战这一策略的核心假设:更大,不必然意味着更昂贵。他们的神经符号视觉语言动作模型在一项严苛的规划 …


