 無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!
無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!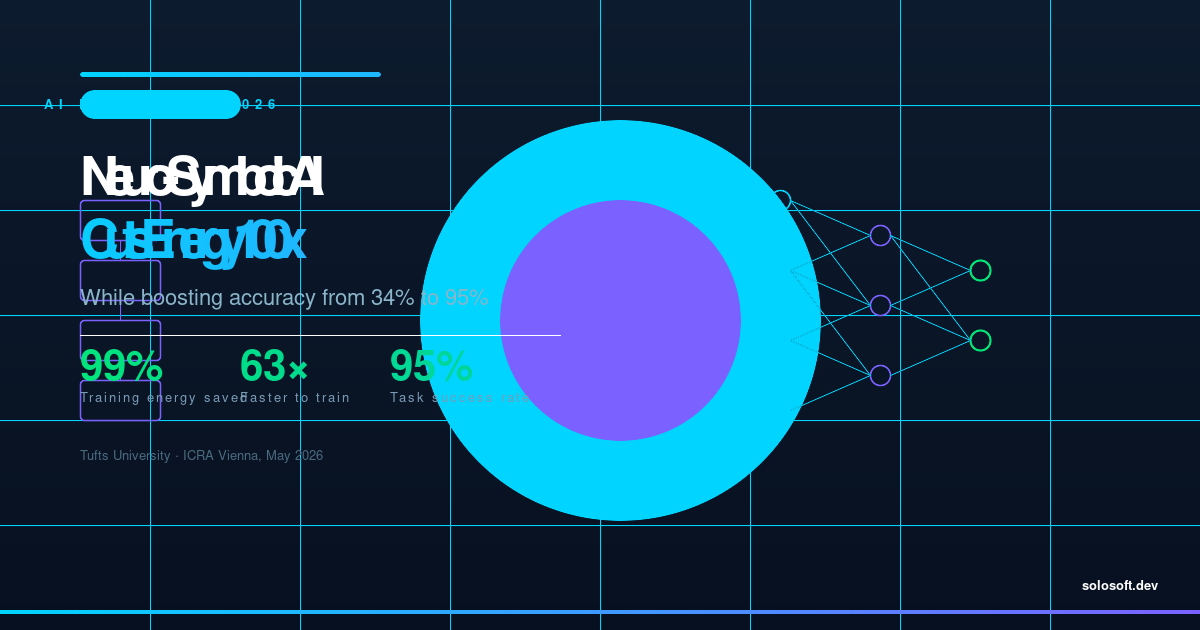
AI 产业在过去五年通过扩展规模来获取更强大的模型——增加参数、消耗更多算力,以令电网运营商从弗吉尼亚到新加坡都警觉的速度吞噬电力。2026 年 4 月,塔夫茨大学研究团队发布了一项成果,从根本挑战这一策略的核心假设:更大,不必然意味着更昂贵。他们的神经符号视觉语言动作模型在一项严苛的规划任务中达到 95% 的成功率,训练期间仅使用标准深度学习模型能耗的 1%,推理期间使用 5%。训练时间从超过 36 小时骤降至 34 分钟。这项研究成果将于 2026 年 5 月在维也纳机器人与自动化国际研讨会发表——恰逢 AI 能源危机从理论隐忧演变为运营紧急状态。超大规模云端厂商正签署数十年的核电购电协议,即使在保守的 AI 采用情境下,数据中心电力需求预计到 2030 年也将增至三倍。一项以 1% 训练能耗实现更高准确率的技术,不仅是学术上的奇珍——它直接挑战了每一家前沿实验室与每一家大规模部署 AI 的企业的资本经济学。
神经符号 AI 是什么?为何此刻格外重要?
神经符号 AI 融合了两个历史上各自独立的研究传统:神经网络,从原始数据中学习统计模式;以及符号推理,以人类组织知识的方式编码结构化规则与逻辑关系。标准深度学习模型将每个问题——包括序列规划任务——都视为模式匹配挑战,需要庞大的训练数据与算力来近似正确行为。神经符号系统先将问题拆解为逻辑子步骤,让符号引擎处理结构,神经组件处理感知。结果是一个推理而非猜测的模型,而推理在计算上远比在数十亿参数上进行暴力梯度下降便宜。
时机至关重要,因为 2026 年是代理式 AI(能够自主规划、决策并执行多步骤工作流程的系统)成为企业标准期望的一年。本季度每一项重大模型发布都强调代理式能力。代理式任务恰恰是符号推理的强项:它们需要可靠的序列决策,而不仅仅是流畅的文本生成。因此,神经符号架构可能比纯粹的 Transformer 方法更符合企业实际希望部署的工作负载。
塔夫茨突破实际上是如何运作的?
塔夫茨团队由 Matthias Scheutz 教授(Karol 家族应用技术教授)领导,围绕机器人操作任务——特别是汉诺塔这个需要在不将较大圆盘放在较小圆盘上的前提下在柱子之间移动圆盘的经典规划问题——构建了他们的模型。该任务需要在多个步骤中进行正确的序列推理,纯统计近似效果极差。
他们的架构将神经感知模块(从视觉输入中识别物体并推断空间关系)与使用经典 AI 规划算法生成明确行动序列的符号规划器配对。神经模块不需要从头学习规划;它只需要足够精确地感知,以向符号规划器提供正确输入。这种分工消除了纯神经模型通过反复试错来内化规划逻辑所需的绝大多数训练样本。
| 指标 | 标准 VLA 模型 | 神经符号模型 |
|---|---|---|
| 任务成功率 | 34% | 95% |
| 训练时间 | 超过 36 小时 | 34 分钟 |
| 训练能耗(相对) | 100% | 1% |
| 推理能耗(相对) | 100% | 5% |
| 架构类型 | 端到端神经网络 | 神经网络 + 符号规划器 |
95% 对 34% 的成功率差距并非噪声——它反映了两种架构在规划方式上的质性差异。标准模型有时能在短序列上碰运气;神经符号模型可靠地解决了完整谜题,因为其符号规划器保证了结构正确性,而神经组件处理了杂乱的现实感知问题。
为何 AI 能耗在 2026 年成为首要问题?
AI 能源需求已从讨论议题升级为实际基础设施约束。训练 GPT-4 级别的模型消耗约 50 GWh。训练下一代万亿参数模型的估计达到 1,000 GWh 以上——相当于一座中型城市的年用电量。推理是更大的长期隐忧:随着企业大规模将 AI 投入生产,推理负载比训练能耗高出一个数量级。
| 基础设施投资 | 组织 | 规模 |
|---|---|---|
| 2025–2026 年签署的核电购电协议 | 微软、Google、亚马逊 | 多座 1–3 GW 机组 |
| 2026 年新增数据中心容量 | 仅美国 | 预计约 30 GW |
| AI 占全球电力份额 | IEA 2030 年预测 | 总消耗量的 3–4% |
| 平均训练一次(前沿 LLM) | 前三实验室 | 50–200 GWh |
经济压力与环境压力同样显著。GPU 算力是 AI 实验室与企业部署最大的单项成本。一个以 1% 训练能耗达到更高准确率的模型,代表训练阶段计算费用潜在的 99 倍降幅——这个数字彻底改变了在资源受限环境(从工业机器人到新兴市场边缘设备)中部署 AI 的商业案例。
这是否挑战了驱动业界的规模定律?
是的——局部且重要地挑战了。Kaplan 等人建立并由 Chinchilla 进一步完善的规模定律描述了模型性能如何随着参数与训练数据同步增加而提升。自 2020 年以来,它一直是前沿 AI 投资的北极星:更多算力意味着更好的模型。
神经符号成果并未推翻通用语言模型的规模定律。它所展示的是:对于结构化的行动导向任务——企业 AI 工作负载中庞大且持续增长的子集——必须扩展神经组件才能达到高准确率的假设是错误的。配对符号推理器的较小神经组件,在具有逻辑结构的任务上,可以超越更大的纯神经系统。
graph TD
A[感知输入<br>摄像头 / 传感器] --> B[神经感知模块<br>物体检测 + 空间映射]
B --> C[符号规划器<br>经典 AI 规划算法]
C --> D[行动序列<br>结构化逐步计划]
D --> E[执行层<br>机器人 / 代理 / 工作流程引擎]
E --> F[任务完成<br>95% 成功率]
G[标准深度学习<br>纯神经端到端] --> H[统计近似<br>34% 成功率]
style A fill:#e8f4f8
style F fill:#d4edda
style H fill:#f8d7da战略意涵是业界将分叉:前沿实验室将继续为开放式推理扩展 Transformer;机器人、自动化与边缘 AI 供应商将越来越多地采用准确、高效且可解释的混合架构。2026 年评估 AI 供应商的企业应明确询问其供应商使用哪种范式,以及是否与实际任务结构相匹配。
这对企业 AI 部署有何意涵?
2026 年 4 月,企业 AI 格局正在迅速整合。尽管 Q1 创投资金创下纪录——全球 3000 亿美元,四家前沿实验室单独获得 1880 亿美元——企业正在将每个用例的 AI 供应商精简至一至两家。主要驱动力是集成成本:将 AI 部署到生产工作流程代价高昂,切换成本快速累积。
神经符号成果为供应商评估引入了新维度。以效率为先的架构降低持续推理成本,使边缘部署成为可行,并生成决策可逐步审计的模型——这是纯神经黑盒难以轻易匹配的合规优势。
flowchart LR
subgraph 传统路径
T1[大型 LLM] --> T2[高计算成本]
T2 --> T3[云端依赖]
T3 --> T4[黑盒决策]
end
subgraph 神经符号路径
N1[混合模型] --> N2[1-5% 能耗]
N2 --> N3[边缘部署可行]
N3 --> N4[可解释步骤]
end
T4 --> C[企业采用摩擦]
N4 --> D[企业采用优势]
style D fill:#d4edda
style C fill:#f8d7da| 企业需求 | 纯神经 LLM | 神经符号混合 |
|---|---|---|
| 可解释性 / 审计轨迹 | 低——统计输出 | 高——符号步骤有日志 |
| 边缘 / 本地部署 | 受模型大小限制 | 低能耗下可行 |
| 法规合规 | 需要事后可解释性工具 | 内置逻辑追踪 |
| 规划问题的任务准确率 | 中——随参数规模提升 | 高——逻辑正确性有保障 |
| 持续推理成本 | 生产规模下高昂 | 潜在降低 20 倍 |
对于 CIO 与 AI 产品负责人而言,实际问题是其最高价值的 AI 用例是否涉及结构化的多步骤推理(神经符号的候选),还是开放式的生成与理解(大型神经模型仍是正确工具)。大多数企业工作流程——供应链优化、临床路径规划、机器人流程自动化、有界域的代码生成——恰好落在神经符号的最佳适用范围内。
FAQ
神经符号 AI 与标准深度学习有何不同? 神经符号 AI 融合了神经网络与符号推理,先将问题拆解为逻辑子步骤,大幅降低所需数据量与计算量,而不是像标准深度学习那样将每个问题视为统计模式匹配挑战。
新的神经符号 AI 模型实际使用多少能源? 训练阶段仅使用标准模型能耗的 1%(节省 99%),训练时间从超过 36 小时缩短至 34 分钟。推理阶段使用 5% 的能源,直接降低云端计算成本并缩小碳足迹。
为了达到节能效果,准确率是否有所牺牲? 不,准确率反而大幅提升。在汉诺塔规划基准测试中达到 95% 的成功率,而标准基准线仅有 34%,因为符号推理确保了逻辑正确性而非统计猜测。
哪些 AI 应用最能受益于神经符号方法? 需要多步骤规划、可解释决策或在严格资源限制下运作的应用,包括机器人、工业自动化、医疗诊断、边缘 AI 部署及企业工作流程自动化。
此突破是否意味着业界将停止扩展大型语言模型? 不,但预示着分叉:前沿实验室继续扩展 LLM 用于通用推理,而行动导向 AI(机器人、代理式工作流程、嵌入式系统)将越来越多地采用效率更高的神经符号架构。两种范式将共存。
神经符号 AI 何时会进入生产部署? 研究将于 2026 年 5 月在维也纳机器人与自动化国际研讨会发表。工业机器人供应商通常在 18 至 36 个月内将研讨会研究转化为生产应用,企业软件平台可能更快。


