 無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!
無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!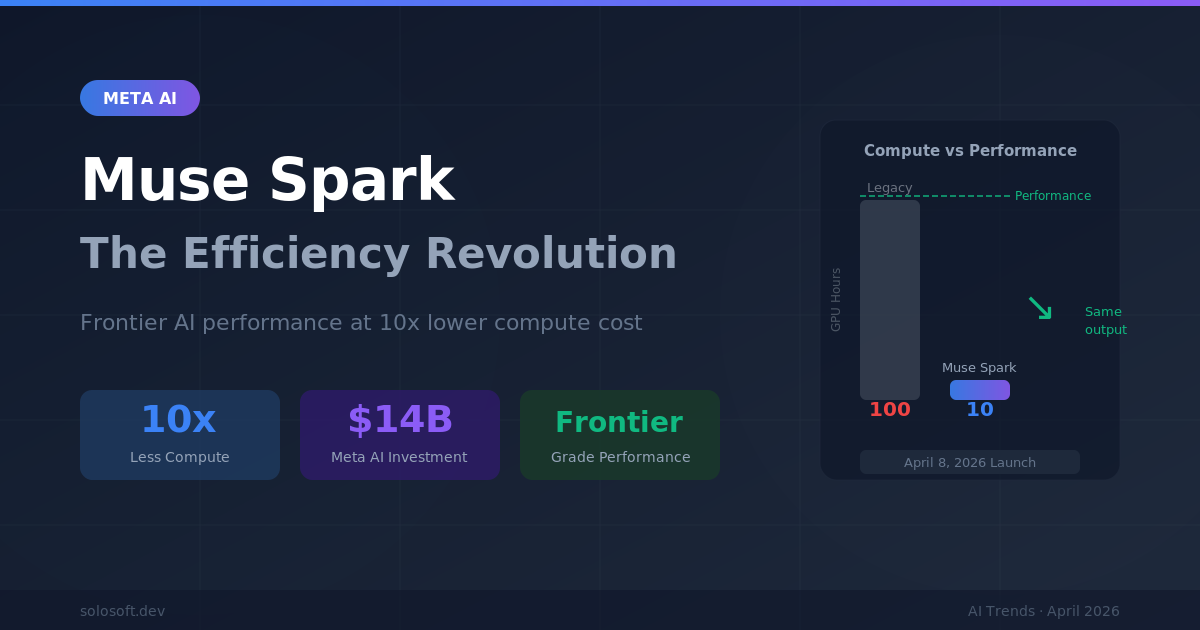
「越大越好」的假設主導了 AI 發展將近十年。2020 年由 OpenAI 研究人員提出的縮放法則指出,向模型投入更多算力與資料能可靠地產生更智慧的系統。這個共識形塑了數兆美元的投資決策、資料中心建設規劃,以及每家主要 AI 實驗室的戰略定位。2026 年 4 月 8 日,Meta 以具體行動挑戰了這個假設:Muse Spark——Meta 自 140 億美元 AI 人才與基礎設施承諾以來的首款重要模型——在多模態推理、健康分析與代理任務完成方面表現出競爭力,所需算力比舊版 Llama 4 據報少了約一個數量級。這不只是一次產品發布,而是對 2026 年 AI 戰略假設的一次壓力測試。
時機意義深遠。OpenAI 近期以 8,520 億美元估值完成了創紀錄的 1,220 億美元融資,投資人押注的是建立在算力規模上的持續主導地位。Google DeepMind 持續大力投資 Gemini Ultra 的 TPU 集群。在此背景下,Meta 以效率優先的訊號所帶來的戰略重量,遠超出模型基準測試本身。若一家資源充沛的實驗室能以成本的一小部分接近前沿效能,單純靠算力支出建立的競爭護城河就會縮窄。對於評估 AI 部署的企業買家、新創公司與政府而言,這項發展重新框架了押注哪些模型、願意支付多少費用的計算邏輯。
Meta Muse Spark 是什麼,為何重要?
Meta Muse Spark 是 2026 年 4 月 8 日發布的多模態基礎模型,結合了強大的推理、健康領域分析與代理能力。這是 Meta 在 2025 年底宣布的 140 億美元投資浪潮——包括高調延攬 Scale AI 創辦人 Alexandr Wang——所誕生的首款旗艦模型。效率提升——以少約一個數量級的算力達到與舊版 Llama 4 相當的效能——標誌著它在技術上的獨特性,而非只是行銷包裝。
| 能力 | Muse Spark | Llama 4(參考) | GPT-4o(估計) |
|---|---|---|---|
| 多模態感知 | ✅ 強 | ✅ 強 | ✅ 強 |
| 推理基準 | 具競爭力 | 基準 | 具競爭力 |
| 代理任務完成 | ✅ 增強 | ⚠️ 有限 | ✅ 強 |
| 訓練算力(相對) | ~0.1x | 1x | ~1.5x |
| 健康領域 | ✅ 專業化 | ⚠️ 通用 | ⚠️ 通用 |
算力減少是最大亮點。提升一個數量級並非漸進式改善——這是架構選擇而非規模正在成為決定性差異化因素的訊號。
為何算力效率成為新的競爭護城河?
因為「多花錢就能贏」的戰略優勢正在侵蝕。過去,能負擔最大訓練規模的實驗室就能贏得能力競賽。Muse Spark 的案例顯示,架構——特別是模型如何將神經網路模式識別與符號推理整合在一起——能夠彌補原始規模的不足。這意味著競爭格局從以資本支出定義的軍備競賽,轉向以研究品質定義的競爭。
經濟邏輯同樣強而有力。以低 10 倍的算力成本,推理在過去被排除在外的市場中變得可行:使用一般商用硬體的農村醫療系統、在有限雲端預算下部署 AI 服務的新興市場政府,以及無法承擔前沿 API 成本的中型企業。民主化不再只是行銷話術——它是更低廉算力的算術結果。
graph TD
A[高昂算力成本] --> B[只有大型企業能負擔前沿 AI]
C[Muse Spark 效率突破] --> D[推理成本降低 10 倍]
D --> E[醫療診斷變得可及]
D --> F[新興市場部署成為可能]
D --> G[中型企業具備競爭力]
D --> H[新代理應用場景解鎖]
B -->|過去狀態| I[AI 使用權集中]
G --> J[AI 使用權分散]Muse Spark 如何改變 AI 部署的經濟學?
它將 AI 採用的損益平衡點移動了一個數量級。試想一家醫院系統每天對 10,000 份病患記錄執行診斷輔助。按過去的前沿模型定價,這樣的工作量每月可能耗費 5 至 8 萬美元。效率提升 10 倍後,相同工作量降至 1 萬美元以下——完全在中型醫院的營運預算範圍內。這並非純粹理論:Meta 已明確將健康列為 Muse Spark 的重點應用領域。
| 部署情境 | 過去成本估計 | Muse Spark 估計 | 可及性變化 |
|---|---|---|---|
| 醫院診斷輔助(每日 1 萬筆) | 6 萬美元/月 | 約 6 千美元/月 | ✅ 中型醫院現可負擔 |
| 法律文件審查(每月 5 萬頁) | 4 萬美元/月 | 約 4 千美元/月 | ✅ 中小型律師事務所可採用 |
| 製造業品管(每日 100 萬次影像檢測) | 12 萬美元/月 | 約 1.2 萬美元/月 | ✅ 與人工品管成本相當 |
| 代理客服(每月 100 萬次互動) | 8 萬美元/月 | 約 8 千美元/月 | ✅ A 輪新創可承擔 |
以上為基於報告算力減少比例與當前 API 定價基準的示意估算,實際成本取決於部署基礎設施與優化程度。
效率提升是真正的突破還是基準測試操弄?
這是正確的問題,保持懷疑是合理的。模型開發者有挑選有利於自身架構與訓練分佈之基準的紀錄。在全面的 MMLU、HELM 與 BIG-Bench 測試組,以及真實世界代理任務上進行獨立評估,是接受效率聲明之前的必要步驟。
話雖如此,所描述的機制——結合神經模式識別與符號推理元件——有其理論基礎。混合架構將規則受限的任務卸載至符號模組,減少了神經網路從範例中學習這些任務的冗餘計算。這在概念上類似於混合專家(MoE)模型的效率提升,後者每個 token 只激活部分參數。
flowchart LR
Input[使用者輸入] --> Router{任務路由器}
Router -->|模式密集型任務| NN[神經網路模組]
Router -->|規則受限型任務| Sym[符號推理模組]
NN --> Merge[輸出聚合器]
Sym --> Merge
Merge --> Output[回應]
style NN fill:#4A90D9,color:#fff
style Sym fill:#F5A623,color:#fff
style Router fill:#7ED321,color:#fff合理的疑慮在於符號模組在分佈邊界之外是否會變得脆弱——在其規則空間之外的邊緣案例上可能退化。Meta 對健康領域的聚焦將對此進行壓力測試:醫療推理同時涉及模式識別(診斷影像)和規則受限邏輯(藥物交互作用檢查),是一個適當的試煉場。
這對 OpenAI、Google 和 Nvidia 意味著什麼?
對於 OpenAI 和 Google DeepMind,Muse Spark 迫使他們重新評估戰略。若競爭對手以低 10 倍的算力達到前沿等級效能,支撐 OpenAI 1,220 億美元融資的敘事——主導地位需要無與倫比的算力規模——至少部分受到了動搖。兩家公司都不會放棄規模擴張;但也都需要展示效率提升。
對於 Nvidia,影響更為複雜。每項任務算力減少 10 倍並不自動意味著 GPU 銷售減少 10 倍——需求彈性效應歷史上會推動需求:更便宜的 AI 解鎖新應用,擴大總體可及市場。然而,若企業買家開始以效率優先模型為基礎規劃部署,升級週期動態將改變,資料中心 GPU 更新節奏可能放緩。
| 利害關係人 | 短期影響 | 長期風險 |
|---|---|---|
| OpenAI | 規模論敘事承壓 | 可能流失對成本敏感的企業客群 |
| Google DeepMind | 被迫加大效率研發投資 | TPU 優勢部分商品化 |
| Nvidia | 需求彈性效應可能抵消效率衝擊 | 若效率增益持續積累,升級週期可能放緩 |
| AWS / Azure / GCP | 每項工作負載所需集群規模縮小 | GPU 供應資本支出可能減少 |
| 企業買家 | 即時降低成本的機會 | 廠商多元化風險上升 |
有哪些值得關注的限制與失敗模式?
效率敘事有其真實的局限性,在做出戰略押注前值得仔細審視。
首先,符號推理模組在分佈邊界上容易脆化。Muse Spark 在健康領域的提升可能無法遷移至創意寫作、程式碼生成或跨文化推理等規則模糊的任務。考慮替換現有模型的企業應執行特定任務評估,而非僅依賴已發布的基準。
其次,多模態效率聲明在圖像與視頻輸入上值得審視。語言效率提升並不自動推廣至高維輸入——算力減少可能集中於文字任務,而圖像處理開銷仍維持不變。
第三,開放與封閉 API 的問題仍懸而未決。若 Meta 以封閉 API 產品形式保留 Muse Spark(而非開源模型權重),民主化論點的成立前提是 Meta 的定價決策,而非架構保證。
常見問題
Meta Muse Spark 是什麼? Meta Muse Spark 是 Meta 於 2026 年 4 月發布的最新基礎模型,在多模態推理與代理任務方面表現卓越,所需算力比舊版 Llama 4 少了約一個數量級。
AI 算力效率為何如此重要? 較低的算力需求可大幅降低訓練與推理成本,讓規模較小的機構也能部署前沿 AI。同時也能縮減能耗與碳足跡,回應外界對大規模 AI 開發的永續性質疑。
Muse Spark 與 GPT-4o 和 Gemini Ultra 相比如何? 早期基準測試顯示,Muse Spark 在推理和多模態任務上的表現與 GPT-4o 相當,但所需 GPU 訓練時間顯著更少。與 Gemini Ultra 在代理基準上的直接比較仍屬初步階段。
Muse Spark 背後 140 億美元投資的意義為何? Meta 在 2025 至 2026 年間承諾投入 140 億美元於 AI 人才與基礎設施,其中包括高調延攬 Alexandr Wang。Muse Spark 是這波投資浪潮中誕生的首款旗艦模型,標誌著 Meta 從跟隨者轉型為前沿競爭者。
算力效率提升意味著 AI 品質的妥協嗎? 不。Muse Spark 的架構在提升效率的同時也改善了準確率,顯示這是真正的架構突破,而非效能與成本的妥協。結合神經網路與符號推理元件似乎是關鍵機制。
哪些產業最受益於更低廉的 AI 推理成本? 醫療診斷、法律文件分析與製造業品管是近期最明確的受益者。
AI 效率是否威脅到 Nvidia 的 GPU 主導地位? 長期而言可能如此。若頂尖模型以少 10 倍的 GPU 時數達成相當結果,原始算力的需求增長可能放緩。不過,更便宜的推理所帶動的需求彈性效應,可能維持甚至增加整體 GPU 需求。
延伸閱讀
- Meta AI 研究部落格 — Muse Spark 技術論文與模型說明的官方來源
- CNBC:Meta 發布自 140 億美元交易以來的首款重要 AI 模型 — 4 月 8 日發布的原始報導
- ScienceDaily:AI 能耗降低 100 倍同時提升準確率 — 神經符號混合效率提升研究
- Stanford HAI AI Index 2026 — AI 能力、成本與普及趨勢的年度基準


