 無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!
無程式碼也能輕鬆打造專業LINE官方帳號!一鍵導入模板,讓AI助你行銷加分!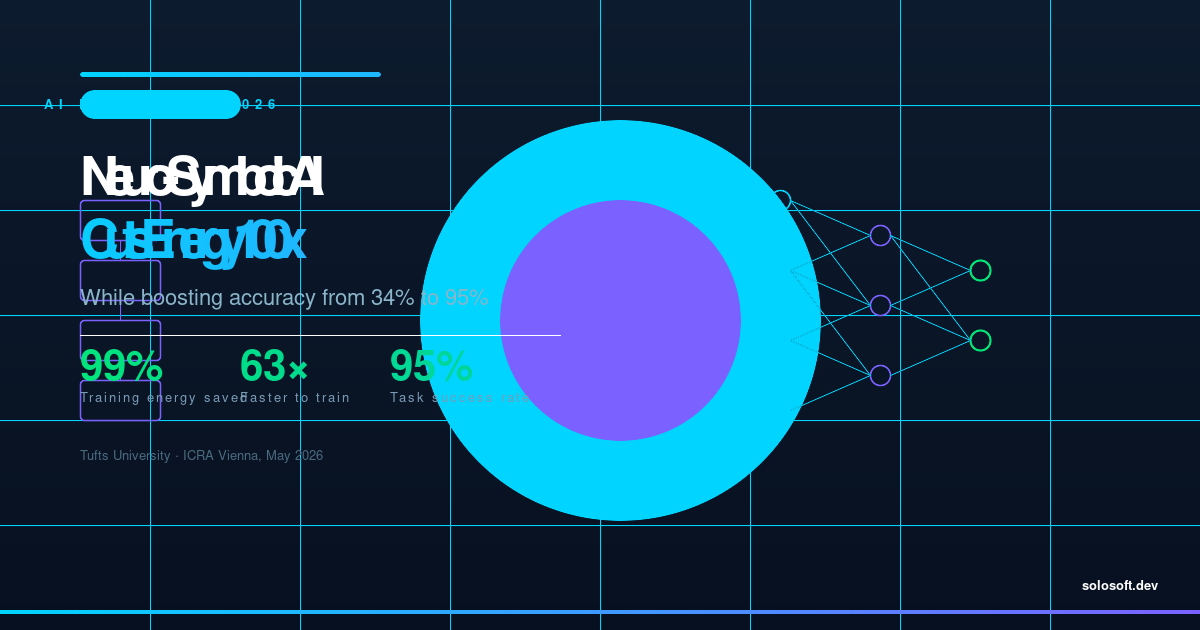
AI 產業在過去五年透過擴展規模來獲取更強大的模型——增加參數、消耗更多算力,以令電網營運商從維吉尼亞到新加坡都警覺的速度吞噬電力。2026 年 4 月,塔夫茨大學研究團隊發布了一項成果,從根本挑戰這一策略的核心假設:更大,不必然意味著更昂貴。他們的神經符號視覺語言動作模型在一項嚴苛的規劃任務中達到 95% 的成功率,訓練期間僅使用標準深度學習模型能耗的 1%,推論期間使用 5%。訓練時間從超過 36 小時崩縮至 34 分鐘。這項研究成果將於 2026 年 5 月在維也納機器人與自動化國際研討會發表——恰逢 AI 能源危機從理論隱憂演變為運營緊急狀態。超大規模雲端業者正簽署數十年的核電購電協議,即使在保守的 AI 採用情境下,資料中心電力需求預計到 2030 年也將增至三倍。一項以 1% 訓練能耗實現更高準確率的技術,不僅是學術上的奇珍——它直接挑戰了每一家前沿實驗室與每一家大規模部署 AI 的企業的資本經濟學。
神經符號 AI 是什麼?為何此刻格外重要?
神經符號 AI 融合了兩個歷史上各自獨立的研究傳統:神經網路,從原始資料中學習統計模式;以及符號推理,以人類組織知識的方式編碼結構化規則與邏輯關係。標準深度學習模型將每個問題——包括序列規劃任務——都視為模式匹配挑戰,需要龐大的訓練資料與算力來近似正確行為。神經符號系統先將問題拆解為邏輯子步驟,讓符號引擎處理結構,神經元件處理感知。結果是一個推理而非猜測的模型,而推理在計算上遠比在數十億參數上進行暴力梯度下降便宜。
時機至關重要,因為 2026 年是代理式 AI(能夠自主規劃、決策並執行多步驟工作流程的系統)成為企業標準期望的一年。本季度每一項重大模型發布都強調代理式能力。代理式任務恰恰是符號推理的強項:它們需要可靠的序列決策,而不僅僅是流暢的文本生成。因此,神經符號架構可能比純粹的 Transformer 方法更符合企業實際希望部署的工作負載。
塔夫茨突破實際上是如何運作的?
塔夫茨團隊由 Matthias Scheutz 教授(Karol 家族應用技術教授)領導,圍繞機器人操作任務——特別是漢諾塔這個需要在不將較大圓盤放在較小圓盤上的前提下在柱子之間移動圓盤的經典規劃問題——構建了他們的模型。該任務需要在多個步驟中進行正確的序列推理,純統計近似效果極差。
他們的架構將神經感知模組(從視覺輸入中識別物件並推斷空間關係)與使用經典 AI 規劃演算法生成明確行動序列的符號規劃器配對。神經模組不需要從頭學習規劃;它只需要足夠精確地感知,以向符號規劃器提供正確輸入。這種分工消除了純神經模型透過反覆試錯來內化規劃邏輯所需的絕大多數訓練樣本。
| 指標 | 標準 VLA 模型 | 神經符號模型 |
|---|---|---|
| 任務成功率 | 34% | 95% |
| 訓練時間 | 超過 36 小時 | 34 分鐘 |
| 訓練能耗(相對) | 100% | 1% |
| 推論能耗(相對) | 100% | 5% |
| 架構類型 | 端對端神經網路 | 神經網路 + 符號規劃器 |
95% 對 34% 的成功率差距並非雜訊——它反映了兩種架構在規劃方式上的質性差異。標準模型有時能在短序列上碰運氣;神經符號模型可靠地解決了完整謎題,因為其符號規劃器保證了結構正確性,而神經元件處理了雜亂的現實感知問題。
為何 AI 能耗在 2026 年成為首要問題?
AI 能源需求已從討論議題升級為實際基礎設施約束。訓練 GPT-4 等級的模型消耗約 50 GWh。訓練下一代兆參數模型的估計達到 1,000 GWh 以上——相當於一座中型城市的年用電量。推論是更大的長期隱憂:隨著企業大規模將 AI 投入生產,推論負載比訓練能耗高出一個數量級。
| 基礎設施投資 | 組織 | 規模 |
|---|---|---|
| 2025–2026 年簽署的核電購電協議 | 微軟、Google、亞馬遜 | 多座 1–3 GW 機組 |
| 2026 年新增資料中心容量 | 僅美國 | 預計約 30 GW |
| AI 佔全球電力份額 | IEA 2030 年預測 | 總消耗量的 3–4% |
| 平均訓練一次(前沿 LLM) | 頂三實驗室 | 50–200 GWh |
經濟壓力與環境壓力同樣顯著。GPU 算力是 AI 實驗室與企業部署最大的單項成本。一個以 1% 訓練能耗達到更高準確率的模型,代表訓練階段計算費用潛在的 99 倍降幅——這個數字徹底改變了在資源受限環境(從工業機器人到新興市場邊緣設備)中部署 AI 的商業案例。
這是否挑戰了驅動業界的規模定律?
是的——局部且重要地挑戰了。Kaplan 等人建立並由 Chinchilla 進一步完善的規模定律描述了模型性能如何隨著參數與訓練資料同步增加而提升。自 2020 年以來,它一直是前沿 AI 投資的北極星:更多算力意味著更好的模型。
神經符號成果並未推翻通用語言模型的規模定律。它所展示的是:對於結構化的行動導向任務——企業 AI 工作負載中龐大且持續增長的子集——必須擴展神經元件才能達到高準確率的假設是錯誤的。配對符號推理器的較小神經元件,在具有邏輯結構的任務上,可以超越更大的純神經系統。
graph TD
A[感知輸入<br>攝影機 / 感測器] --> B[神經感知模組<br>物件偵測 + 空間映射]
B --> C[符號規劃器<br>經典 AI 規劃演算法]
C --> D[行動序列<br>結構化逐步計畫]
D --> E[執行層<br>機器人 / 代理 / 工作流程引擎]
E --> F[任務完成<br>95% 成功率]
G[標準深度學習<br>純神經端對端] --> H[統計近似<br>34% 成功率]
style A fill:#e8f4f8
style F fill:#d4edda
style H fill:#f8d7da戰略意涵是業界將分叉:前沿實驗室將繼續為開放式推理擴展 Transformer;機器人、自動化與邊緣 AI 供應商將越來越多地採用準確、高效且可解釋的混合架構。2026 年評估 AI 供應商的企業應明確詢問其供應商使用哪種典範,以及是否與實際任務結構相匹配。
這對企業 AI 部署有何意涵?
2026 年 4 月,企業 AI 格局正在迅速整合。儘管 Q1 創投資金創下紀錄——全球 3000 億美元,四家前沿實驗室單獨獲得 1880 億美元——企業正在將每個用例的 AI 供應商精簡至一至兩家。主要驅動力是整合成本:將 AI 部署到生產工作流程代價高昂,轉換成本快速累積。
神經符號成果為供應商評估引入了新維度。以效率為先的架構降低持續推論成本,使邊緣部署成為可行,並生成決策可逐步稽核的模型——這是純神經黑盒難以輕易匹配的合規優勢。
flowchart LR
subgraph 傳統路徑
T1[大型 LLM] --> T2[高計算成本]
T2 --> T3[雲端依賴]
T3 --> T4[黑盒決策]
end
subgraph 神經符號路徑
N1[混合模型] --> N2[1-5% 能耗]
N2 --> N3[邊緣部署可行]
N3 --> N4[可解釋步驟]
end
T4 --> C[企業採用摩擦]
N4 --> D[企業採用優勢]
style D fill:#d4edda
style C fill:#f8d7da| 企業需求 | 純神經 LLM | 神經符號混合 |
|---|---|---|
| 可解釋性 / 稽核軌跡 | 低——統計輸出 | 高——符號步驟有日誌 |
| 邊緣 / 本地部署 | 受模型大小限制 | 低能耗下可行 |
| 法規合規 | 需要事後可解釋性工具 | 內建邏輯追蹤 |
| 規劃問題的任務準確率 | 中——隨參數規模提升 | 高——邏輯正確性有保障 |
| 持續推論成本 | 生產規模下高昂 | 潛在降低 20 倍 |
對於 CIO 與 AI 產品負責人而言,實際問題是其最高價值的 AI 用例是否涉及結構化的多步驟推理(神經符號的候選),還是開放式的生成與理解(大型神經模型仍是正確工具)。大多數企業工作流程——供應鏈優化、臨床路徑規劃、機器人流程自動化、有界域的程式碼生成——恰好落在神經符號的最佳適用範圍內。
FAQ
神經符號 AI 與標準深度學習有何不同? 神經符號 AI 融合了神經網路與符號推理,先將問題拆解為邏輯子步驟,大幅降低所需資料量與計算量,而不是像標準深度學習那樣將每個問題視為統計模式匹配挑戰。
新的神經符號 AI 模型實際使用多少能源? 訓練階段僅使用標準模型能耗的 1%(節省 99%),訓練時間從超過 36 小時縮短至 34 分鐘。推論階段使用 5% 的能源,直接降低雲端計算成本並縮小碳足跡。
為了達到節能效果,準確率是否有所犧牲? 不,準確率反而大幅提升。在漢諾塔規劃基準測試中達到 95% 的成功率,而標準基準線僅有 34%,因為符號推理確保了邏輯正確性而非統計猜測。
哪些 AI 應用最能受益於神經符號方法? 需要多步驟規劃、可解釋決策或在嚴格資源限制下運作的應用,包括機器人、工業自動化、醫療診斷、邊緣 AI 部署及企業工作流程自動化。
此突破是否意味著業界將停止擴展大型語言模型? 不,但預示著分叉:前沿實驗室繼續擴展 LLM 用於通用推理,而行動導向 AI(機器人、代理式工作流程、嵌入式系統)將越來越多地採用效率更高的神經符號架構。兩種典範將共存。
神經符號 AI 何時會進入生產部署? 研究將於 2026 年 5 月在維也納機器人與自動化國際研討會發表。工業機器人供應商通常在 18 至 36 個月內將研討會研究轉化為生產應用,企業軟體平台可能更快。


